
机器学习之LogisticRegression详解
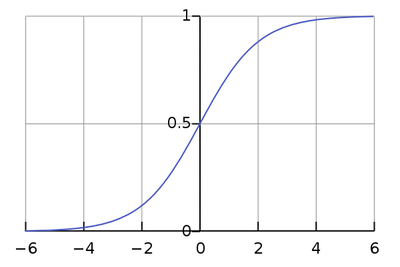
逻辑回归使用了逻辑函数,将任意实数t([ t $\epsilon$ R ])输入,转化成0到1的实数值,逻辑函数一般采用Sigmoid函数,其表达式及示意图如下:
\[ \sigma(t)=\dfrac{e^t}{1+e^t} \]
1. 二元分类
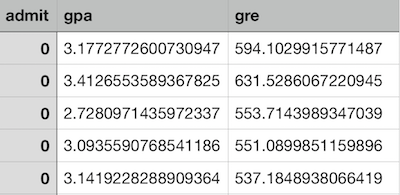
本例所用数据表请右键点击下载:admissions.csv
import pandas as pd
import matplotlib.pyplot as plt
admissions = pd.read_csv("admissions.csv")
plt.scatter(admissions['gpa'], admissions['admit'])
plt.show()
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression()
logistic_model.fit(admissions[["gpa"]], admissions["admit"])
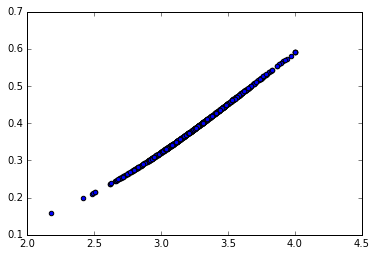
pred_probs = logistic_model.predict_proba(admissions[["gpa"]])
# [:,0]返回标签是0的行,[:,1]返回标签是1的行
plt.scatter(admissions["gpa"], pred_probs[:,1])
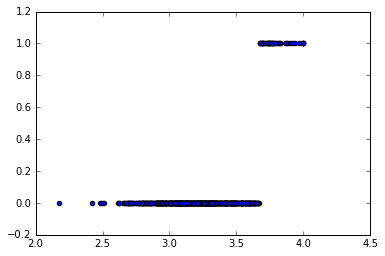
fitted_labels = logistic_model.predict(admissions[["gpa"]])
plt.scatter(admissions["gpa"], fitted_labels)
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
# 训练模型
admissions = pd.read_csv("admissions.csv")
model = LogisticRegression()
model.fit(admissions[["gpa"]], admissions["admit"])
# 模型预测
labels = model.predict(admissions[["gpa"]])
admissions["predicted_label"] = labels
print(admissions["predicted_label"].value_counts()) #返回0和1的个数分别为598和46
# 计算准确率
admissions["actual_label"] = admissions["admit"]
matches = admissions["predicted_label"] == admissions["actual_label"]
correct_predictions = admissions[matches]
print(correct_predictions.head())
accuracy = len(correct_predictions) / len(admissions)
print(accuracy) #64.6%
准确率仅能告诉我们一个数字,不能告诉我们训练的模型在新的数据集上的预测性能。准确率也不能区分二元分类模型在不同类别上的预测结果。以下列出二元分类问题的四种结果:
- Sensitivity or True Positive Rate - The proportion of applicants that were correctly admitted
- Specificity or True Negative Rate - The proportion of applicants that were correctly rejected
\[ TPR=\dfrac{\text{True Positives}}{\text{True Positives} + \text{False Negatives}} \]
- How effective is this model at identifying positive outcomes?
\[ TNR=\dfrac{\text{True Negatives}}{\text{False Positives} + \text{True Negatives}} \]
- How effective is this model at identifying negative outcomes?
true_positive_filter = (admissions["predicted_label"] == 1) & (admissions["actual_label"] == 1)
true_positives = len(admissions[true_positive_filter])
false_negative_filter = (admissions["predicted_label"] == 0) & (admissions["actual_label"] == 1)
false_negatives = len(admissions[false_negative_filter])
sensitivity = true_positives / (true_positives + false_negatives)
print(sensitivity)
true_negative_filter = (admissions["predicted_label"] == 0) & (admissions["actual_label"] == 0)
true_negatives = len(admissions[true_negative_filter])
false_positive_filter = (admissions["predicted_label"] == 1) & (admissions["actual_label"] == 0)
false_positives = len(admissions[false_positive_filter])
specificity = (true_negatives) / (false_positives + true_negatives)
print(specificity)
2. 多元分类
本例所用数据表请右键点击下载:auto.csv
import pandas as pd
cars = pd.read_csv("auto.csv")
print(cars.head())
unique_regions = cars["origin"].unique()
print(unique_regions) #三元分类问题 1: North America, 2: Europe, 3: Asia
#cylinders, year虽然是数值栏,但这类离散变量应看成类别变量
dummy_cylinders = pd.get_dummies(cars["cylinders"], prefix="cyl")
cars = pd.concat([cars, dummy_cylinders], axis=1)
dummy_years = pd.get_dummies(cars["year"], prefix="year")
cars = pd.concat([cars, dummy_years], axis=1)
cars = cars.drop("year", axis=1)
cars = cars.drop("cylinde")
print(cars.head())
# 划分training 和 test集
shuffled_rows = np.random.permutation(cars.index)
shuffled_cars = cars.iloc[shuffled_rows]
highest_train_row = int(cars.shape[0] * .70)
train = shuffled_cars.iloc[0:highest_train_row]
test = shuffled_cars.iloc[highest_train_row:]
# one-vs-all approach 训练模型
from sklearn.linear_model import LogisticRegression
unique_origins = cars["origin"].unique()
unique_origins.sort()
models = {}
features = [c for c in train.columns if c.startswith("cyl") or c.startswith("year")]
for origin in unique_origins:
model = LogisticRegression()
X_train = train[features]
y_train = train["origin"] == origin
model.fit(X_train, y_train)
models[origin] = model
# 模型预测
testing_probs = pd.DataFrame(columns=unique_origins)
for origin in unique_origins:
X_test = test[features]
testing_probs[origin] = models[origin].predict_proba(X_test)[:,1]
# Dataframe method .idxmax()方法返回分类结果列
predicted_origins = testing_probs.idxmax(axis=1)
print(predicted_origins)
Written on June 27, 2018