
机器学习之K-Nearest Neighbors详解
问题: 你是airbnb平台的房东,怎么给自己的房子定租金?
分析: 租客根据airbnb平台上的租房信息,主要包括价格、卧室数量、房屋类型、位置等等挑选自己满意的房子。给房子定租金是跟市场动态息息相关的,同样类型的房子我们收费太高租客不租,收费太低收益不好。 解答: 收集跟我们房子条件差不多的一些房子信息,确定跟我们房子最相近的几个求定价的平均值,以此作为我们房子的租金。这就是K-Nearest Neighbors,k近邻算法。k-近邻算法的核心思想是未标记样本的类别,由距离其最近的k个邻居投票决定。
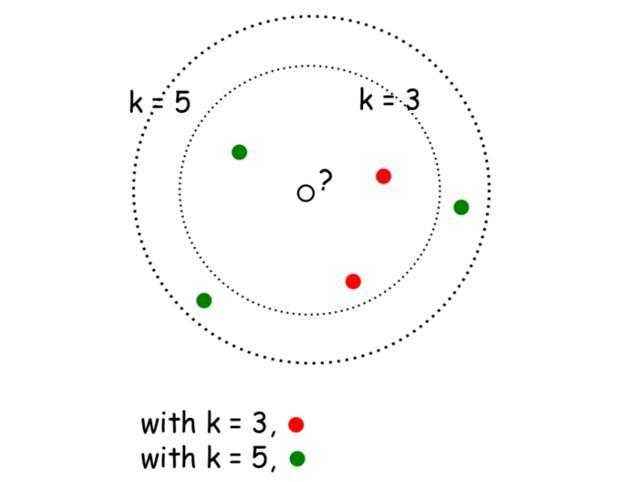
1.根据k近邻算法定义直接编写代码。目标是理解逻辑关系,仅考虑单变量的影响。
import pandas as pd
import numpy as np
dc_listings = pd.read_csv("dc_airbnb.csv")
stripped_commas = dc_listings['price'].str.replace(',', '')
stripped_dollars = stripped_commas.str.replace('$', '')
dc_listings['price'] = stripped_dollars.astype('float')
train_df = dc_listings.iloc[0:2792]
test_df = dc_listings.iloc[2792:]
def predict_price(new_listing):
temp_df = train_df.copy()
temp_df['distance'] = temp_df['accommodates'].apply(lambda x: np.abs(x - new_listing))
temp_df = temp_df.sort_values('distance')
nearest_neighbor_prices = temp_df.iloc[0:5]['price']
predicted_price = nearest_neighbor_prices.mean()
return(predicted_price)
test_df['predicted_price'] = test_df['accommodates'].apply(predict_price)
# MAE(mean absolute error), MSE(mean squared error), RMSE(root mean squared error)
test_df['squared_error'] = (test_df['predicted_price'] - test_df['price'])**(2)
mse = test_df['squared_error'].mean()
rmse = mse ** (1/2)
print(rmse)
2. 利用sklearn.neighbors.KNeighborsRegressor()
import pandas as pd
import numpy as np
np.random.seed(1)
dc_listings = pd.read_csv('dc_airbnb.csv')
dc_listings = dc_listings.loc[np.random.permutation(len(dc_listings))]
stripped_commas = dc_listings['price'].str.replace(',', '')
stripped_dollars = stripped_commas.str.replace('$', '')
dc_listings['price'] = stripped_dollars.astype('float')
print(dc_listings.info())
# drop columns contain non-numerical values
drop_columns = ['room_type', 'city', 'state', 'latitude', 'longitude', 'zipcode', 'host_response_rate', 'host_acceptance_rate', 'host_listings_count']
dc_listings = dc_listings.drop(drop_columns, axis=1)
# the 2 columns have a large number of missing values
dc_listings = dc_listings.drop(['cleaning_fee', 'security_deposit'], axis=1)
# remove rows containing missing values
dc_listings = dc_listings.dropna(axis=0)
print(dc_listings.isnull().sum())
normalized_listings = (dc_listings - dc_listings.mean())/(dc_listings.std())
normalized_listings['price'] = dc_listings['price']
from sklearn.neighbors import KNeighborsRegressor
train_df = normalized_listings.iloc[0:2792]
test_df = normalized_listings.iloc[2792:]
features = train_df.columns.tolist()
features.remove('price')
knn = KNeighborsRegressor(n_neighbors=5, algorithm='brute')
knn.fit(train_df[features], train_df['price'])
predictions = knn.predict(test_df[features])
mse = mean_squared_error(test_df['price'], predictions)
rmse = mse ** (1/2)
print(mse)
print(rmse)
3. 手动超参优化(Hyperparameter Optimization)
import pandas as pd
train_df = pd.read_csv('dc_airbnb_train.csv')
test_df = pd.read_csv('dc_airbnb_test.csv')
import matplotlib.pyplot as plt
%matplotlib inline
hyper_params = [x for x in range(1,21)]
mse_values = list()
features = train_df.columns.tolist()
features.remove('price')
for hp in hyper_params:
knn = KNeighborsRegressor(n_neighbors=hp, algorithm='brute')
knn.fit(train_df[features], train_df['price'])
predictions = knn.predict(test_df[features])
mse = mean_squared_error(test_df['price'], predictions)
mse_values.append(mse)
plt.scatter(hyper_params, mse_values)
4. 交叉验证(Cross Validation)
holdout validation:训练集-验证集二划分验证
import numpy as np
import pandas as pd
dc_listings = pd.read_csv("dc_airbnb.csv")
stripped_commas = dc_listings['price'].str.replace(',', '')
stripped_dollars = stripped_commas.str.replace('$', '')
dc_listings['price'] = stripped_dollars.astype('float')
shuffled_index = np.random.permutation(dc_listings.index)
dc_listings = dc_listings.reindex(shuffled_index)
split_one = dc_listings.iloc[0:1862].copy()
split_two = dc_listings.iloc[1862:].copy()
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error
train_one = split_one
test_one = split_two
train_two = split_two
test_two = split_one
# First half
model = KNeighborsRegressor()
model.fit(train_one[["accommodates"]], train_one["price"])
test_one["predicted_price"] = model.predict(test_one[["accommodates"]])
iteration_one_rmse = mean_squared_error(test_one["price"], test_one["predicted_price"])**(1/2)
# Second half
model.fit(train_two[["accommodates"]], train_two["price"])
test_two["predicted_price"] = model.predict(test_two[["accommodates"]])
iteration_two_rmse = mean_squared_error(test_two["price"], test_two["predicted_price"])**(1/2)
avg_rmse = np.mean([iteration_two_rmse, iteration_one_rmse])
print(iteration_one_rmse, iteration_two_rmse, avg_rmse)
k-fold cross-validation (根据概念自定义方法)
dc_listings.loc[dc_listings.index[0:745], "fold"] = 1
dc_listings.loc[dc_listings.index[745:1490], "fold"] = 2
dc_listings.loc[dc_listings.index[1490:2234], "fold"] = 3
dc_listings.loc[dc_listings.index[2234:2978], "fold"] = 4
dc_listings.loc[dc_listings.index[2978:3723], "fold"] = 5
print(dc_listings['fold'].value_counts())
print("\n Num of missing values: ", dc_listings['fold'].isnull().sum())
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
fold_ids = [1,2,3,4,5]
def train_and_validate(df, folds):
fold_rmses = []
for fold in folds:
# Train
model = KNeighborsRegressor()
train = df[df["fold"] != fold]
test = df[df["fold"] == fold].copy()
model.fit(train[["accommodates"]], train["price"])
# Predict
labels = model.predict(test[["accommodates"]])
test["predicted_price"] = labels
mse = mean_squared_error(test["price"], test["predicted_price"])
rmse = mse**(1/2)
fold_rmses.append(rmse)
return(fold_rmses)
rmses = train_and_validate(dc_listings, fold_ids)
print(rmses)
avg_rmse = np.mean(rmses)
print(avg_rmse)
k-fold cross-validation(sklearn方法)
from sklearn.model_selection import cross_val_score, KFold
kf = KFold(5, shuffle=True, random_state=1)
model = KNeighborsRegressor()
mses = cross_val_score(model, dc_listings[["accommodates"]], dc_listings["price"], scoring="neg_mean_squared_error", cv=kf)
rmses = np.sqrt(np.absolute(mses))
avg_rmse = np.mean(rmses)
print(rmses)
print(avg_rmse)
# 超参优化
num_folds = [3, 5, 7, 9, 10, 11, 13, 15, 17, 19, 21, 23]
for fold in num_folds:
kf = KFold(fold, shuffle=True, random_state=1)
model = KNeighborsRegressor()
mses = cross_val_score(model, dc_listings[["accommodates"]], dc_listings["price"], scoring="neg_mean_squared_error", cv=kf)
rmses = np.sqrt(np.absolute(mses))
avg_rmse = np.mean(rmses)
std_rmse = np.std(rmses)
print(str(fold), "folds: ", "avg RMSE: ", str(avg_rmse), "std RMSE: ", str(std_rmse))
5. 总结
从k-近邻算法的核心思想以及以上编码过程可以看出,该算法是基于实例的学习方法,因为它完全依靠训练集里的实例。该算法不需什么数学方法,很容易理解。但是非常不适合应用在大数据集上,因为k-近邻算法每一次预测都需要计算整个训练集的数据到待预测数据的距离,然后增序排列,计算量巨大。
如果能用数学函数来描述数据集的特征变量与目标变量的关系,那么一旦用训练集获得了该数学函数,预测就是简简单单的数学计算问题了。计算复杂度大大降低。下一篇我们来看看线性回归算法模型。
Enjoy the journey!
Written on June 25, 2018